
- Rows should be named
- All data stored should be the same type
- Each column should contain the same number of data items ✅

- Columns should be named ✅
Explanation:
- Each column in a data frame must contain the same number of data items for structural consistency.
- Columns should be named for clarity and usability.
- Rows do not have to be named, contrary to common assumptions.
- Data in a single column can vary in type, unlike matrices.
- Tibbles can create row names
- Tibble can change the data type of inputs
- Tibbles make printing easier ✅

- Tibbles make changing the names of variables easier.
Explanation:
Tibbles automatically print only the first 10 rows and as many columns as fit the screen, avoiding overwhelming outputs for large datasets. Tibbles do not automatically change variable names or data types.
- True ✅

- False
Explanation:
Tidy data principles ensure that:
- Each variable is a column.
- Each observation is a row.
- Each type of observational unit is in a separate table.
- str()
- head()
- mutate() ✅

- colnames()
Explanation:
The mutate() function (from the dplyr package) is specifically designed to add new columns or modify existing ones in a data frame. Functions like str() and head() are for inspecting and previewing data, not altering it.
- rename_with()
- rename()
- select()
- clean_names() ✅

Explanation:
The clean_names() function (from the janitor package) automatically standardizes column names to be consistent, unique, and easier to use in R by converting them to snake_case and ensuring no duplicates.

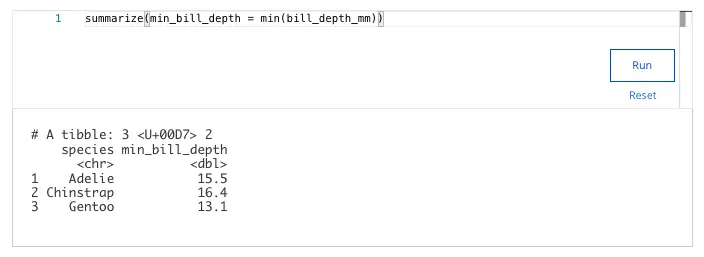
- 32.1 ✅

- 34.0
- 33.5
- 33.1
Explanation:
Using the arrange() function with the column bill_length_mm sorts the data in ascending order by default. The smallest value in the sorted column is 32.1 mm.
- unite() ✅

- arrange()
- select()
- separate()
Explanation:
The unite() function (from the tidyr package) combines multiple columns into a single column. It is ideal for combining first and last names into one column. The opposite function, separate(), splits one column into multiple columns.
- mean() ✅

- cor() ✅
- sd() ✅
- ggplot2()
Explanation:
mean(): Calculates the average of a numeric vector.cor(): Computes the correlation between two numeric vectors, showing how strongly related they are.sd(): Calculates the standard deviation of a numeric vector, indicating the spread of data.- ggplot2(): Incorrect. This is a visualization package, not a statistical function.
- sd(x)
- mean(y)
- cor(x,y) ✅

- sd(y)
Explanation:
The cor() function calculates the correlation coefficient, which measures the strength and direction of the linear relationship between variables x and y.
- probable
- final
- desired
- predicted ✅

Explanation:
Bias measures the difference between the actual and predicted outcomes, helping analysts evaluate if the model systematically overestimates or underestimates results.
- Tibbles can create row names
- Tibbles automatically only preview the first 10 rows of data ✅

- Tibbles can automatically change the names of variables
- Tibbles automatically only preview as many columns as fit on screen ✅
Explanation:
Tibbles are a modern take on data frames in R. They are designed to handle large datasets efficiently by previewing a manageable portion of data and avoiding console clutter.
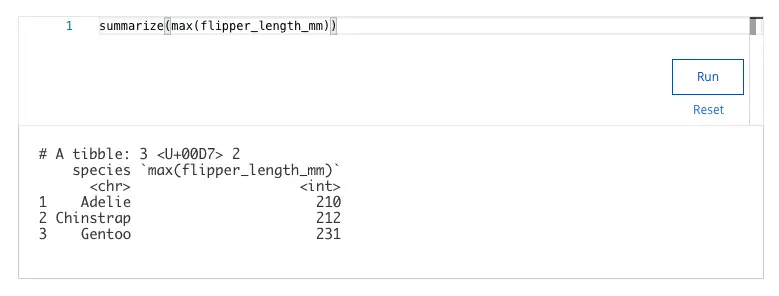
- 200
- 212
- 210
- 231 ✅
Explanation:
The summarize() function calculates summary statistics, such as max(). The maximum flipper length for the Gentoo species is 231 mm.
- unite(stores, “location”, city, state, sep=”,”) ✅
- unite(stores, “location”, city, sep=”,”)
- unite(stores, city, state, sep=”,”)
- unite(stores, “location”, city, state)
Explanation:
The unite() function combines multiple columns into one, with a specified separator (,).
- rename_with(tolower, cars)
- rename_with(cars, toupper)
- rename_with(toupper, cars)
- rename_with(cars, tolower) ✅
Explanation:
The rename_with() function allows the application of a function, such as tolower, to column names.
- mean()
- bias()
- sd()
- cor() ✅
Explanation:
The cor() function calculates the correlation coefficient, measuring the strength and direction of the linear relationship between variables.
- package()
- colnames()
- library()
- str() ✅
Explanation:
The str() function provides the structure of an object, including the data types and values of each column in a data frame.
- separate(sales, location, into=c(“country”, “city” ), sep=”, “)
- separate(sales, location, into=c(“city”, “country”), sep=”, “) ✅
- untie(sales, location, into=c(“city”, “country”), sep=”, “)
- separate(sales, location, into=c(“country”, “city” ), sep=” “)
Explanation:
The separate() function splits a column into multiple columns based on a separator (, in this case).

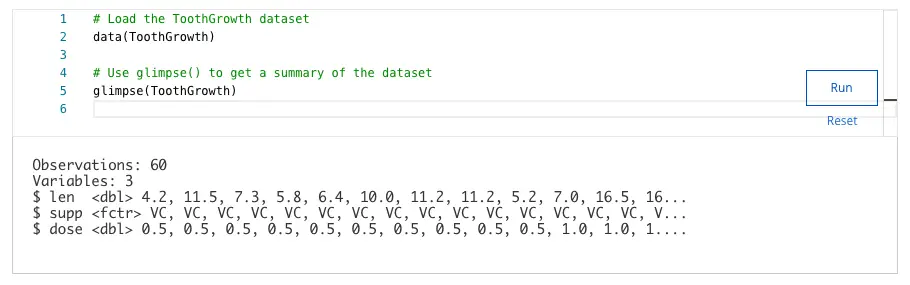
- 2 ✅
- 3
- 60
- 1
Explanation:
The glimpse() function reveals that the ToothGrowth dataset contains two types of data: numeric and factor.
- The average difference between the actual and predicted values ✅
- The maximum difference between the actual and predicted values
- The total average of the values
- The minimum difference between the actual and predicted values
Explanation:
The bias() function evaluates the systematic error in predictions by calculating the average difference between actual and predicted values.
- penguins %>% filter(island == “Torgersen”)
- penguins %>% filter(island = “Torgersen”)
- penguins %>% filter(island <> “Torgersen”)
- penguins %>% filter(island != “Torgersen”) ✅
Explanation:
The filter() function excludes rows based on a logical condition. island != "Torgersen" removes all rows where the island is “Torgersen.”
Good and thanks for your help
No worries!